213 Usage of chem_id and mass_area_id
Usage of keys
In survey litterfall, use the keys for following:
- chem_id: to connect dry weights (in table LFD) with chemical values (in table LFC)
- mass_area_id: to connect dry weights (in table LFD) with mass area values (in table LFA)
The link between LFC/LFA and LFD is a 1:n link. This means, that while each key may only occur once in the LFC or once in LFA, it can be assigned to multiple dry weights in LFD associated with pooled fractions, pooled tree species or collection periods. Thus, every possible dry weight pooling combination can be clearly assigned to one chemical or one mass/area measurement.
Construction pattern
Keys for linking dry weight values to both chemical and mass/area values follow the same pattern.
| Key | Pattern | Example |
|---|---|---|
| chem_id | C_[partner_code]_[code_plot]_[survey_year]_[consecutive number for each plot-year] | C_50_101_2003_1 |
| mass_area_id | A_[partner_code]_[code_plot]_[survey_year]_[consecutive number for each plot-year] | A_1_84_2014_4 |
For example, chem_id C_50_12_2002_3 can be translated into: Switzerland - Plot 12 - survey year 2002 - 3rd chemical analysis (for this year and plot).
Case study with pooled samples
The principle behind
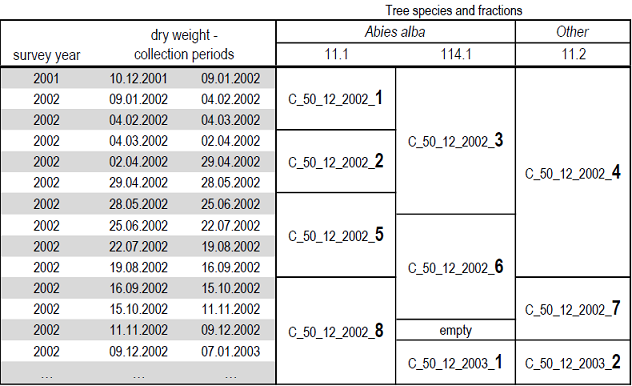
Let’s take plot 12 in Switzerland (code 50) and survey year 2002 as an example, where samples were pooled over different time periods. In accordance to the pattern as shown above, the chem_id has to start like this: C_50_12_2002_
Furthermore, let’s imagine that for this survey year, a total of 7 pooled samples were chemically analysed. Each of these analyses results in a further consecutive number, which is appended to the end of the key and thus uniquely identifies each analysis: C_50_12_2002_1 up to C_50_12_2002_7.
The following overview illustrates how the litterfall was pooled separately by tree species and fractions over several time periods and how this affected the chem_id.
Implementation in tables
Clear assignment is most important
The order of the consecutive number does not matter. But it is of most imortance that each analyse has a unique key and correctly assigned to the samples in LFD!